 深入了解ByteBuf
深入了解ByteBuf
# ByteBuf功能介绍
从功能角度而言,ByteBuffer完全可以满足NIO编程的需要,但是由于NIO编程的复杂性, ByteBuffer也有其局限性,它的主要缺点如下。
- ByteBuffer长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的POJO对象大于ByteBuffer的容量时,会发生索引越界异常;
- ByteBuffer只有一个标识位置的指针 position,读写的时候需要手工调用flip()和rewind()等,使用者必须小心谨慎地处理这些API,否则很容易导致程序处理失败
- ByteBuffer的API功能有限,一些高级和实用的特性它不支持,需要使用者自己 编程实现
为了弥补这些不足,Nety提供了自己的 ByteBuffer 实现-ByteBuf。
# 1.1 工作原理
ByteBuf通过两个位置指针来协助缓冲区的读写操作,读操作使用 readerIndex,写操作使用 writerIndex。
* +-------------------+------------------+------------------+
* | discardable bytes | readable bytes | writable bytes |
* | | (CONTENT) | |
* +-------------------+------------------+------------------+
* | | | |
* 0 <= readerIndex <= writerIndex <= capacity
2
3
4
5
6
readerIndex和 writerIndex的取值一开始都是0,随着数据的写入 writerIndex 会增加,读取数据会使 readerlndex 增加,但是它不会超过 writerlndex。
在读取之后,**(0 ~ readerlndex)**就被视为 discard 的,调用 discarDreadBytes 方法,可以释放这部分空间,它的作用类似ByteBuffer的compact方法。 **(readerIndex ~ writerIndex)**之间的数据是可读取的,等价于ByteBuffer position 和 limit 之间的数据。 **(writerIndex ~ capacity)**之间的空间是可写的,等价于 ByteBuffer limit和 capacity之间的可用空间。
* BEFORE discardReadBytes()
*
* +-------------------+------------------+------------------+
* | discardable bytes | readable bytes | writable bytes |
* +-------------------+------------------+------------------+
* | | | |
* 0 <= readerIndex <= writerIndex <= capacity
*
*
* AFTER discardReadBytes()
*
* +------------------+--------------------------------------+
* | readable bytes | writable bytes (got more space) |
* +------------------+--------------------------------------+
* | | |
* readerIndex (0) <= writerIndex (decreased) <= capacity
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
由于写操作不修改 readerIndex指针,读操作不修改 writerIndex指针,因此读写之间不再需要调整位置指针,这极大地简化了缓冲区的读写操作,避免了由于遗漏或者不熟悉flip()操作导致的功能异常。
* BEFORE clear()
*
* +-------------------+------------------+------------------+
* | discardable bytes | readable bytes | writable bytes |
* +-------------------+------------------+------------------+
* | | | |
* 0 <= readerIndex <= writerIndex <= capacity
*
* AFTER clear()
*
* +---------------------------------------------------------+
* | writable bytes (got more space) |
* +---------------------------------------------------------+
* | |
* 0 = readerIndex = writerIndex <= capacity
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 1.2 ByteBuf动态扩展
通常情况下,对 ByteBuffer 进行put操作时,如果缓冲区剩余可写空间不够,就会发生 BufferOverflowException。为了避免发生这个问题,通常在进行put操作的时候会对剩余可用空间进行校验。如果剩余空间不足,需要重新创建一个新的 ByteBuffer,并将之前的 ByteBuffer 复制到新创建的 ByteBuffer中,最后释放老的 ByteBuffer。对此,为了防止 ByteBuffer 溢出,都会对可用空间进行校验,导致了代码冗余,而且可能引入其他问题。
为了解决这个问题,ByteBuf 对 write 操作进行了封装,由 ByteBuf 的 write 操作负责进行剩余可用空间的校验,如果可用缓冲区不足,ByteBuf会自动进行动态扩展,对于使用者而言,不需要关心底层的校验和扩展细节,只要不超过设置的最大缓冲区容量即可。当可用空间不足时, ByteBuf会帮助我们实现自动扩展,这极大地降低了 ByteBuf 的学习和使用成本,提升了开发效率。校验和扩展的相关代码:
@Override
public ByteBuf writeByte(int value) {
ensureWritable0(1);
_setByte(writerIndex++, value);
return this;
}
2
3
4
5
6
当进行 write 操作时会对需要 write 的字节进行校验,如果可写的字节数小于需要写入的字节数,并且需要写入的字节数小于可写的最大字节数时,对缓冲区进行动态扩展。
由于NIO的Channel读写的参数都是 ByteBuffer 因此,Nety的 ByteBuf 接口必须提供API方便的将 Bytebuf 转换成 ByteBuffer,或者将 ByteBuffer包装成 ByteBuf。考虑到性能,应该尽量避免缓冲区的复制,内部实现的时候可以考虑聚合一个 ByteBuffer 的私有指针用来代表 ByteBuffer.
final void ensureWritable0(int minWritableBytes) {
ensureAccessible();
if (minWritableBytes <= writableBytes()) {
return;
}
final int writerIndex = writerIndex();
if (checkBounds) {
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
}
// Normalize the current capacity to the power of 2.
int minNewCapacity = writerIndex + minWritableBytes;
int newCapacity = alloc().calculateNewCapacity(minNewCapacity, maxCapacity);
int fastCapacity = writerIndex + maxFastWritableBytes();
// Grow by a smaller amount if it will avoid reallocation
if (newCapacity > fastCapacity && minNewCapacity <= fastCapacity) {
newCapacity = fastCapacity;
}
// Adjust to the new capacity.
capacity(newCapacity);
}
protected final void ensureAccessible() {
if (checkAccessible && !isAccessible()) {
throw new IllegalReferenceCountException(0);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# ByteBuf源码分析
# 2.1 ByteBuf主要继承关系
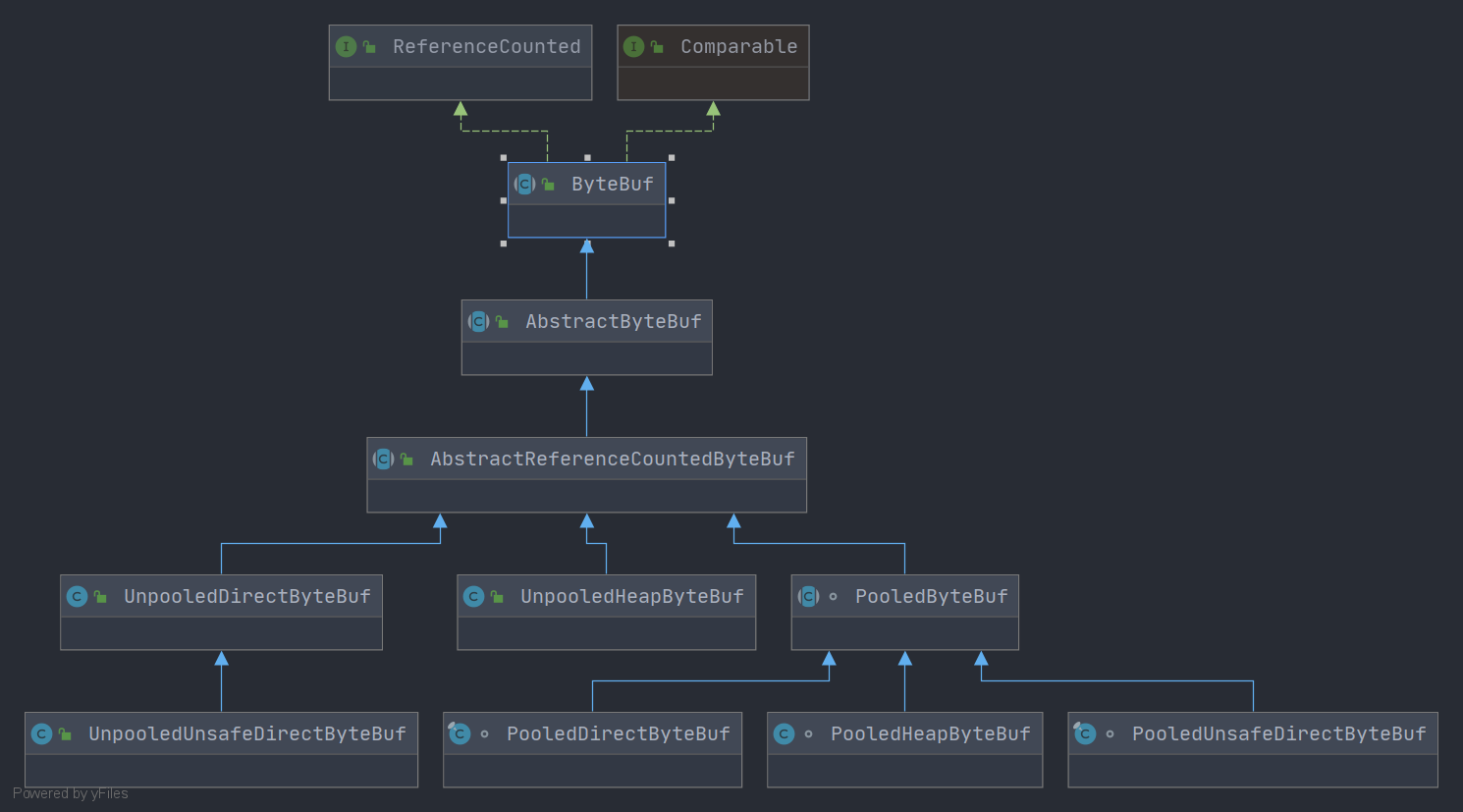
从内存分配的角度看, ByteBuf可以分为两类:
- 堆内存( HeapByteBuf)字节缓冲区:特点是内存的分配和回收速度快,可以被JVM自动回收;缺点就是如果进行 Socket的IO读写,需要额外做一次内存复制,将堆内存对应的缓冲区复制到内核 Channel中,性能会有一定程度的下降。
- 直接内存( DirectByteBuf)字节缓冲区:非堆内存,它在堆外进行内存分配,相比于堆内存,它的分配和回收速度会慢一些,但是将它写入或者从 Socket Channel中读取时,由于少了一次内存复制,速度比堆内存快。
正是因为各有利弊,所以Nety提供了多种 ByteBuf供开发者使用,经验表明, ByteBuf的最佳实践是在IO通信线程的读写缓冲区使用 DirectByteBuf,后端业务消息的编解码模块使用 HeapByteBuf。这样组合可以达到性能最优。
从内存回收角度看, ByteBuf也分为两类:基于对象池的 ByteBuf和普通 ByteBuf。两者的主要区别就是基于对象池的 ByteBuf 可以重用 ByteBuf 对象,它自己维护了一个内存池,可以循环利用创建的 ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁GC测试表明使用内存池后的Nety在高负载、大并发的冲击下内存和GC更加平稳。
尽管推荐使用基于内存池的 ByteBuf,但是内存池的管理和维护更加复杂,使用起来也需要更加谨慎。因此,Nety提供了灵活的策略供使用者来做选择。
# 2.2 AbstractByteBuf
# 成员变量
首先,像读索引、写索引、mark、最大容量等公共属性需要定义。我们重点关注下 leakDetector,它被定义为 static,意味着所有的 ByteBuf实例共享同个 ResourceLeakDetector对象。 ResourceLeakDetector用于检测对象是否泄漏。
static final ResourceLeakDetector<ByteBuf> leakDetector =
ResourceLeakDetectorFactory.instance().newResourceLeakDetector(ByteBuf.class);
int readerIndex;
int writerIndex;
private int markedReaderIndex;
private int markedWriterIndex;
private int maxCapacity;
2
3
4
5
6
7
8
在 AbstractByteBuf中并没有定义 ByteBuf的缓冲区实现,例如byte数组或者 DirectByteBuffer。原因显而易见,因为 AbstractByteBuf并不清楚子类到底是基于堆内存还是直接内存,因此无法提前定义。
# 读操作
无论子类如何实现ByteBuf,它们最终都是操作ByteBuffer,功能相同且操作结果等价。ByteBuf提供了多种类型的read操作,将以readBytes(byte[] dst, int dstIndex, int length)为例,其他操作类似,不做过多的介绍。源代码如下:
@Override
public ByteBuf readBytes(byte[] dst, int dstIndex, int length) {
checkReadableBytes(length); // 1
getBytes(readerIndex, dst, dstIndex, length); // 2
readerIndex += length; // 3
return this;
}
2
3
4
5
6
7
- 校验缓冲区可用空间。如果读取的长度小于0,则抛出 IllegalArgumentException 异常提示参数非法:如果可写的字节数小于需要读取的长度,则抛出 IndexOutOfBoundsException 异常。
- 调用getBytes,从当前的读索引开始,复制 length个字节到目标byte数组中。由于不同的子类复制操作的技术实现细节不同,因此该方法由子类实现。
- 对读索引递增。
# 写操作
与读操作类似,将以writeBytes(byte[] src, int srcIndex, int length)为例,源码如下。它的功能是将源数组的srcIndex开始,srcIndex+length 截至的源数组写入到当前ByteBuf。
@Override
public ByteBuf writeBytes(byte[] src, int srcIndex, int length) {
ensureWritable(length); // 1
setBytes(writerIndex, src, srcIndex, length); // 2
writerIndex += length; // 3
return this;
}
2
3
4
5
6
7
- 校验写入数组长度。如果写入的数组长度小于0,则抛出 IllegalArgumentException 异常提示参数非法:如果写入的数组字节数小于当前可写的长度则说明可写入,直接返回。如果写入的字节数组长度大于可以动态扩展的最大可写字节数,说明缓冲区无法写入超过其最大容量的字节数组,抛出 IndexOutOfBoundsException 异常。
- 调用setBytes将源数组的srcIndex开始,srcIndex+length 截至的源数组写入到当前ByteBuf。由于不同的子类复制操作的技术实现细节不同,因此该方法由子类实现。
- 对写索引递增。
Netty的 ByteBuffer可以动态扩展,为了保证安全性,允许使用者指定最大的容量。在容量范围内,可以先分配个较小的初始容量,后面不够用再动态扩展,这样可以达到功能和性能的最优组合。
calculateNewCapacity 方法的实现:首先需要重新计算下扩展后的容量,它有一个参数,等于 writerIndex+ minWritableBytes,也就是满足要求的最小容量。
@Override
public int calculateNewCapacity(int minNewCapacity, int maxCapacity) {
checkPositiveOrZero(minNewCapacity, "minNewCapacity");
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}
final int threshold = CALCULATE_THRESHOLD; // 4 MiB page
if (minNewCapacity == threshold) {
return threshold;
}
// If over threshold, do not double but just increase by threshold.
if (minNewCapacity > threshold) {
int newCapacity = minNewCapacity / threshold * threshold;
if (newCapacity > maxCapacity - threshold) {
newCapacity = maxCapacity;
} else {
newCapacity += threshold;
}
return newCapacity;
}
// Not over threshold. Double up to 4 MiB, starting from 64.
int newCapacity = 64;
while (newCapacity < minNewCapacity) {
newCapacity <<= 1;
}
return Math.min(newCapacity, maxCapacity);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
首先设置门限阈值为4M,当需要的新容量正好等于门限阈值,则使用阈值作为新的缓冲区容量。如果新申请的内存空间大于阈值,不能采用倍增的方式(防止内存膨胀和浪费)扩张内存,采用每次步进4M的方式进行内存扩张。扩张的时候需要对扩张后的内存和最大内存( maxCapacity)进行比较,如果大于缓冲区的最大长度,则使用 maxCapacity 作为扩容后的缓冲区容量。如果扩容后的新容量小于阈值,则以64为计数进行倍增,直到倍增后的结果大于或等于需要的容量值。
重新计算完动态扩张后的目标容量后,需要重新创建个新的缓冲区,将原缓冲区的内容复制到新创建的 ByteBuf中,最后设置读写索引和mark标签等。由于不同的子类会对应不同的复制操作,所以该方法依然是个抽象方法,由子类负责实现。
# 2.3 AbstractReferenceCountedByteBuf
该类主要是对引用进行计数,类似于JM内存回收的对象引用计数器,用于跟踪对象的分配和销毁,做自动内存回收。
private static final long REFCNT_FIELD_OFFSET =
ReferenceCountUpdater.getUnsafeOffset(AbstractReferenceCountedByteBuf.class, "refCnt");
private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> AIF_UPDATER =
AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt");
private static final ReferenceCountUpdater<AbstractReferenceCountedByteBuf> updater =
new ReferenceCountUpdater<AbstractReferenceCountedByteBuf>() {
@Override
protected AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> updater() {
return AIF_UPDATER;
}
@Override
protected long unsafeOffset() {
return REFCNT_FIELD_OFFSET;
}
};
// Value might not equal "real" reference count, all access should be via the updater
@SuppressWarnings("unused")
private volatile int refCnt = updater.initialValue();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- REFCNT_FIELD_OFFSET:它用于标识 refCnt字段在 AbstractReferenceCountedByteBuf 中的内存地址,该内存地址的获取是JDK实现强相关的,如果使用SUN的JDK,它通过
sun.misc.Unsafe的PlatformDependent.objectFieldOffset接口来获得, ByteBuf的实现子类 UnpooledUnsafeDirectByteBuf和PooledUnsafeDirectByteBuf会使用到这个偏移量。 - AIF_UPDATER:它是AtomicIntegerFieldUpdater类型变量,通过原子的方式对成员变量进行更新等操作,以实现线程安全,消除锁。
- 最后定义了一个 volatile 修饰的 refCnt 字段用于跟踪对象的引用次数,使用 volatile 是为了解决多线程并发访问的可见性问题。