 Netty系列-传统BIO编程
Netty系列-传统BIO编程
# Netty系列-传统BIO编程
网络编程的基本模型是 Client/Server模型,也就是两个进程之间进行相互通信,其中服务端提供位置信息(绑定的IP地址和监听端口),客户端通过连接操作向服务端监听的地址发起连接请求,通过三次握手建立连接,如果连接建立成功,双方就可以通过网络套接字( Socket)进行通信。在基于传统同步阻塞模型开发中, ServerSocket负责绑定IP地址,启动监听端口Socket负责发起连接操作。连接成功之后,双方通过输入和输出流进行同步阻塞式通信。
# 传统 BI/O
同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。BIO通信(一请求一应答)模型图如下(图源网络,原出处不明):
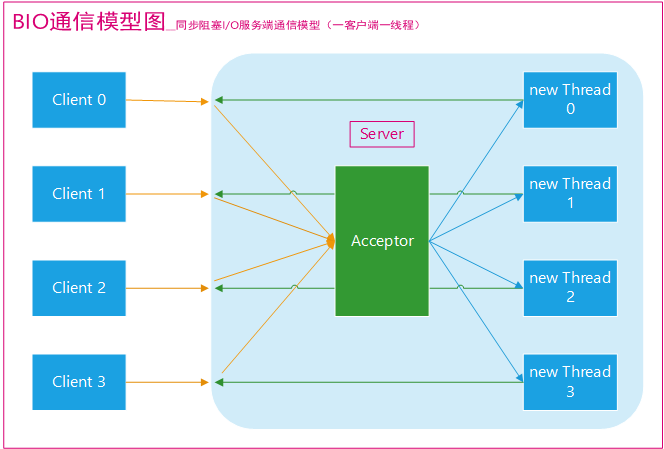
采用 BIO 通信模型 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在while(true) 循环中服务端会调用 accept() 方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接,如上图所示。
如果要让 BIO 通信模型 能够同时处理多个客户端请求,就必须使用多线程**(主要原因是socket.accept()、socket.read()、socket.write() 涉及的三个主要函数都是同步阻塞的)**,也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的 一请求一应答通信模型 。我们可以设想一下如果这个连接不做任何事情的话就会造成不必要的线程开销,不过可以通过 线程池机制 改善,线程池还可以让线程的创建和回收成本相对较低。使用FixedThreadPool 可以有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远大于 M),下面一节"伪异步 BIO"中会详细介绍到。
我们再设想一下当客户端并发访问量增加后这种模型会出现什么问题?
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
缺陷:
到此为止,BIO主要的问题在于每当有一个新的客户端请求接入时,服务端必须创建一个新的线程处理新接入的客户端链路,一个线程只能处理一个客户端连接。在高性能服务器应用领域,往往需要面向成千上万个客户端的并发连接,这种模型显然无法满足高性能、高并发接入的场景。
# 伪异步I/O
为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化一一一后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N.通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。伪异步IO模型:
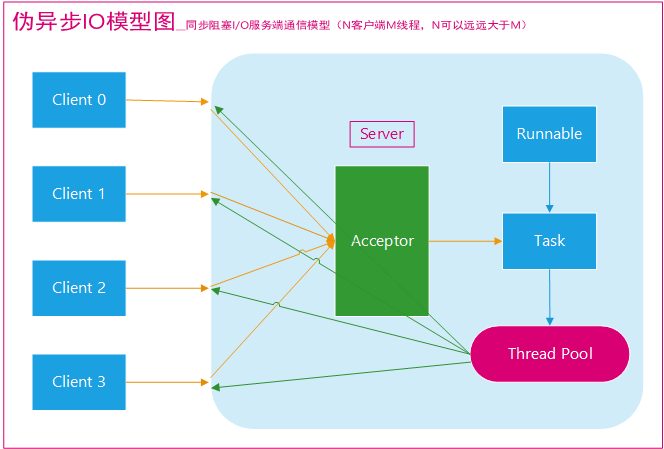
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍然是同步阻塞的BIO模型,因此无法从根本上解决问题。
public class Client {
public static void main(String[] args) {
new Thread(() -> {
try {
Socket socket = new Socket("127.0.0.1", 33333);
while (true) {
try {
socket.getOutputStream()
.write((new Date() + ": hello world")
.getBytes());
Thread.sleep(2000);
} catch (Exception e) { }
}
} catch (IOException e) {
}
}).start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class Server {
public static void main(String[] args) throws IOException {
ServerSocket socketS = new ServerSocket(33333);
new Thread(()->{
try {
handle(socketS);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
static void handle(ServerSocket serverSocket) throws IOException {
while(true) {
Socket socket = serverSocket.accept();
new Thread(()->{
int len = 0;
byte[] bytes = new byte[1024];
try {
InputStream inputStream = socket.getInputStream();
while ((len = inputStream.read(bytes)) != -1) {
System.out.println(new String(bytes,0,len));
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 总结
在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。